Background:
One of the simplest explanation for fit issues in machine learning models can be found here, which essentially ties the accuracy of trained model with new/unseen data to the bias and variance present in training dataset, it also addresses ways to find a balance between both variance and bias.
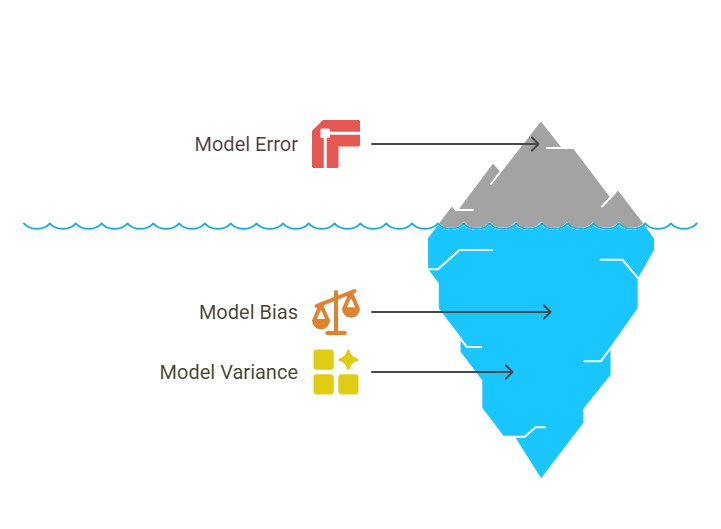
Hyperparameter tuning is a process for improving model performance. By carefully selecting and adjusting hyperparameters, we can:
- Reduce overfitting by controlling model complexity.
- Mitigate underfitting by ensuring the model has enough capacity to learn from the data.
- Achieve a balanced model that generalizes well to both training and new, unseen data.
This balance is key to avoiding the extremes of overfitting and underfitting, ensuring that the model not only learns well from the training data but also performs effectively on real-world data.
By systematically adjusting the model’s complexity and training behavior to find the optimal balance for a given dataset, the overfitting and underfitting issues can be addressed to a significant extent- this can be done by tuning the parameters of the ML model.
Hyperparameters vs. Model Parameters:
- Model Parameters: These are internal variables of the model that are learned from the training data during the training process. Examples include the coefficients in a linear regression model or the weights in a neural network.
- Hyperparameters: These are external configuration variables that are set by the user before the model training process begins. They control the behavior of the learning algorithm itself and directly influence the model’s structure, complexity, and how fast it learns.
How to Select These Values (Hyperparameter Tuning):
The values chosen in the code are good initial guesses or sensible defaults, but they are rarely the optimal values for a specific dataset. The process of finding the best combination of hyperparameters for a given model and dataset is called hyperparameter tuning.
The general approach:
- Start with Sensible Defaults/Common Ranges: The values in your code are excellent for this step. They represent a good balance of performance and computational efficiency to get a first look at how the models perform.
- Define a Search Space: For each hyperparameter you want to tune, define a range of values you believe might work well.
- Example for
n_estimators:[50, 100, 200, 500, 1000] - Example for
learning_rate:[0.01, 0.05, 0.1, 0.2] - Example for
max_depth:[5, 10, 15, 20]
- Example for
- Choose a Tuning Strategy:
- Manual Search: Adjusting parameters by hand based on experience and intuition. (Good for initial exploration, but inefficient for complex tuning).
- Grid Search (
GridSearchCVinscikit-learn):- How it works: Defines a grid of all possible combinations of specified hyperparameter values and trains/evaluates a model for every combination.
- Pros: Guarantees finding the best combination within the defined grid.
- Cons: Can be computationally very expensive and time-consuming, especially with many parameters or wide ranges.
- Random Search (
RandomizedSearchCVinscikit-learn):- How it works: Defines a distribution (or list) of hyperparameter values and samples a fixed number of random combinations from that distribution.
- Pros: Often finds a good set of hyperparameters much faster than Grid Search because it explores the search space more efficiently, especially when some hyperparameters have a much larger impact than others.
- Cons: Not guaranteed to find the absolute best combination, but usually finds a “good enough” one.
- Bayesian Optimization (e.g., using libraries like
Hyperopt,Optuna):- How it works: Uses a probabilistic model to select the next promising hyperparameter combination based on the results of previous evaluations. It learns from past trials to intelligently explore the search space.
- Pros: Generally more efficient than Grid or Random Search, especially for high-dimensional hyperparameter spaces, as it tries to minimize the number of expensive model training runs.
- Cons: More complex to set up.
- Use Cross-Validation: During tuning, evaluate each hyperparameter combination using cross-validation (e.g., K-Fold cross-validation). This ensures that the chosen parameters generalize well to unseen data and helps prevent overfitting to the specific training-test split.
- Monitor Performance: Track a chosen evaluation metric (e.g., F1-score for classification) to determine which parameter combinations perform best. MLflow, as used in your code, is excellent for this.
- Iterate and Refine: Hyperparameter tuning is often an iterative process. Start with broader ranges, then narrow down the search space around the best-performing values.
use these steps to systematically find hyperparameters that optimize their model’s performance for a given task.