Since the dataset we have is high quality we may not need extensive filtering and preprocessing however some datasets are not as good as these and would require multiple stages of processing and filtering. it is of utmost importance to ensure data is filtered and transformed into meaningful format before it is used for training.
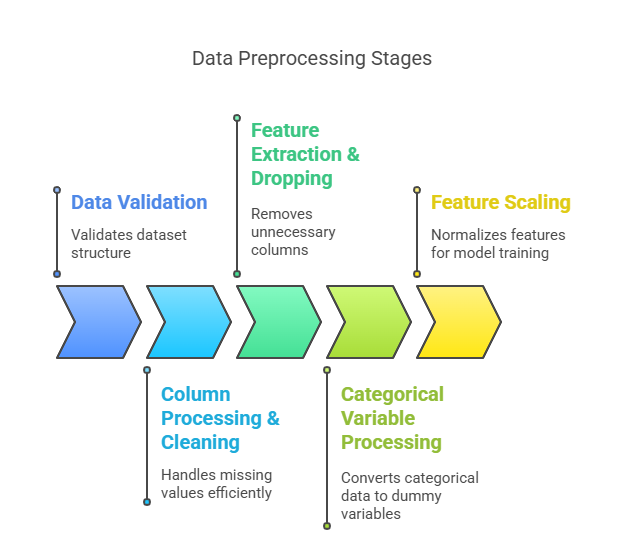
The preprocessing in this code follows 5 main stages
- Data Validation
- Validates that the required ‘Label’ column exists in the dataset
- Ensures the input data structure is correct
- Column Processing & Cleaning
- Identifies column data types (numeric vs non-numeric)
- Handles missing values differently based on data type:
- Numeric columns: Fills nulls with chunked mean calculation for memory efficiency
- Non-numeric columns: Fills nulls with ‘NA’
- Feature Extraction & Dropping
- Removes undesired columns like “Flow Bytes/s”, “Flow Packets/s”, “Flow ID”, “Src IP”, “Dst IP”, “Timestamp”
- Separates features (X) from labels (y)
- Categorical Variable Processing
- Identifies categorical columns (non-numeric types)
- Converts categorical variables to dummy variables using one-hot encoding
- Uses int8 dtype for memory efficiency
- Feature Scaling
- Applies StandardScaler to normalize features
- Processes data in batches for memory efficiency
- Fits the scaler on the first batch, then transforms subsequent batches
- Encodes labels using LabelEncoder
Below is the DataPreprocessor class which includes all the methods described above to preprocess the data:
class DataPreprocessor:
def __init__(self, batch_size=10000):
self.scaler = StandardScaler()
self.label_encoder = LabelEncoder()
self.batch_size = batch_size
self.progress = None
self.feature_groups = {
'packet_features': {
'required': {'Total Fwd Packets', 'Total Backward Packets'},
'derived': ['packet_ratio', 'packet_rate']
},
'byte_features': {
'required': {'Total Length of Fwd Packets', 'Total Length of Bwd Packets'},
'derived': ['byte_ratio', 'byte_rate']
},
'flow_features': {
'required': {'Flow Duration'},
'derived': ['packet_rate', 'byte_rate']
}
}
self.absolutely_required = {'Label'}
self.feature_names = None
self.cat_columns = None
def transform(self, df: pd.DataFrame) -> pd.DataFrame:
try:
if self.feature_names is None:
raise ValueError("Preprocessor has not been fitted. Call `preprocess_data` first.")
dtypes = self.get_column_dtypes(df)
for col in df.columns:
if 'float' in dtypes[col] or 'int' in dtypes[col]:
df[col] = self.process_numeric_column(df[col])
else:
df[col] = df[col].fillna('NA')
cols_to_drop = ["Flow Bytes/s", "Flow Packets/s", "Flow ID",
"Src IP", "Dst IP", "Timestamp"]
existing_cols = [col for col in cols_to_drop if col in df.columns]
df = df.drop(columns=existing_cols)
if self.cat_columns:
df = pd.get_dummies(df, columns=self.cat_columns, dtype=np.int8)
df = df.reindex(columns=self.feature_names, fill_value=0)
scaled_data = []
for i in range(0, len(df), self.batch_size):
batch = df.iloc[i:i + self.batch_size]
scaled_batch = self.scaler.transform(batch)
scaled_data.append(scaled_batch)
return pd.DataFrame(np.vstack(scaled_data), columns=self.feature_names)
except Exception as e:
logging.error(f"Error in data transformation: {str(e)}")
raise
def get_feature_names_out(self):
if self.feature_names is None:
raise ValueError("Feature names are not available. Call `preprocess_data` first.")
return self.feature_names
def get_column_dtypes(self, df: pd.DataFrame) -> Dict[str, str]:
return {col: str(dtype) for col, dtype in df.dtypes.items()}
def process_numeric_column(self, series: pd.Series) -> pd.Series:
if series.isnull().any():
chunk_means = []
chunk_counts = []
for chunk in np.array_split(series, max(1, len(series) // 10000)):
chunk_means.append(chunk.mean())
chunk_counts.append(len(chunk))
overall_mean = np.average(chunk_means, weights=chunk_counts)
series = series.fillna(overall_mean)
return series.transpose()
def preprocess_data(self, df: pd.DataFrame) -> Tuple[pd.DataFrame, np.ndarray]:
try:
self.progress = ProgressLogger(total_steps=5)
self.progress.update("Validating input data")
if 'Label' not in df.columns:
raise ValueError("Label column missing from dataset")
self.progress.update("Processing columns")
dtypes = self.get_column_dtypes(df)
for col in tqdm(df.columns, desc="Processing columns"):
if 'float' in dtypes[col] or 'int' in dtypes[col]:
df[col] = self.process_numeric_column(df[col])
else:
df[col] = df[col].fillna('NA')
self.progress.update("Feature extraction")
cols_to_drop = ["Flow Bytes/s", "Flow Packets/s", "Flow ID",
"Src IP", "Dst IP", "Timestamp"]
existing_cols = [col for col in cols_to_drop if col in df.columns]
df = df.drop(columns=existing_cols)
X = df.drop('Label', axis=1)
y = df['Label'].copy()
self.progress.update("Processing categorical variables")
cat_columns = [col for col, dtype in dtypes.items()
if 'float' not in dtype and 'int' not in dtype
and col in X.columns]
if cat_columns:
X = pd.get_dummies(X, columns=cat_columns, dtype=np.int8)
self.progress.update("Scaling features")
scaled_data = []
for i in tqdm(range(0, len(X), self.batch_size), desc="Scaling batches"):
batch = X.iloc[i:i + self.batch_size]
if i == 0:
scaled_batch = self.scaler.fit_transform(batch)
else:
scaled_batch = self.scaler.transform(batch)
scaled_data.append(scaled_batch)
X = pd.DataFrame(np.vstack(scaled_data), columns=X.columns)
y = self.label_encoder.fit_transform(y)
self.feature_names = X.columns
return X, y
except Exception as e:
logging.error(f"Error in data preprocessing: {str(e)}")
raise
def enhance_features(self, df: pd.DataFrame) -> pd.DataFrame:
try:
enhanced_dfs = []
for start_idx in range(0, len(df), self.batch_size):
end_idx = min(start_idx + self.batch_size, len(df))
batch = df.iloc[start_idx:end_idx].copy()
for group, features in self.feature_groups.items():
required_cols = features['required']
if all(col in batch.columns for col in required_cols):
if group == 'packet_features':
batch['packet_ratio'] = np.divide(
batch['Total Fwd Packets'],
batch['Total Backward Packets'].replace(0, 1),
out=np.zeros(len(batch), dtype=float),
where=batch['Total Backward Packets'] != 0
)
elif group == 'byte_features':
batch['byte_ratio'] = np.divide(
batch['Total Length of Fwd Packets'],
batch['Total Length of Bwd Packets'].replace(0, 1),
out=np.zeros(len(batch), dtype=float),
where=batch['Total Length of Bwd Packets'] != 0
)
else:
for derived in features['derived']:
batch[derived] = 0
missing_cols = required_cols - set(batch.columns)
for col in missing_cols:
batch[col] = 0
enhanced_dfs.append(batch)
del batch
gc.collect()
return pd.concat(enhanced_dfs, axis=0, ignore_index=True)
except Exception as e:
logging.error(f"Error in feature enhancement: {str(e)}")
raiseThese would be used before the model training is started.